Introduction
At CIRCL (Computer Incident Response Center Luxembourg), we faced the challenge of evaluating vulnerabilities with only partial information often just a textual description.
To address this, we built an NLP model using the existing dataset from Vulnerability Lookup. The entire solution has now been released, including integration into the free online service and the open-source code. With this model, you can obtain the VLAI vulnerability score even when no existing score is available, by assessing severity based solely on the description.
Below, you’ll find the complete process we developed for the VLAI Severity models, which can be applied to many other use cases.
Datasets
Among the datasets we provide, a key one is dedicated to vulnerability scoring and features CPE data, CVSS scores, and detailed descriptions.
This dataset is updated daily.
Sources of the data:
- CVE Program (enriched with data from vulnrichment and Fraunhofer FKIE)
- GitHub Security Advisories
- PySec advisories
- CSAF Red Hat
- CSAF Cisco
The licenses for each security advisory feed are listed here:
Get started with the dataset
import json
from datasets import load_dataset
dataset = load_dataset("CIRCL/vulnerability-scores")
vulnerabilities = ["CVE-2012-2339", "RHSA-2023:5964", "GHSA-7chm-34j8-4f22", "PYSEC-2024-225"]
filtered_entries = dataset.filter(lambda elem: elem["id"] in vulnerabilities)
for entry in filtered_entries["train"]:
print(json.dumps(entry, indent=4))
For each vulnerability, you will find all assigned severity scores and associated CPEs.
Models
How We Build Our VLAI Model
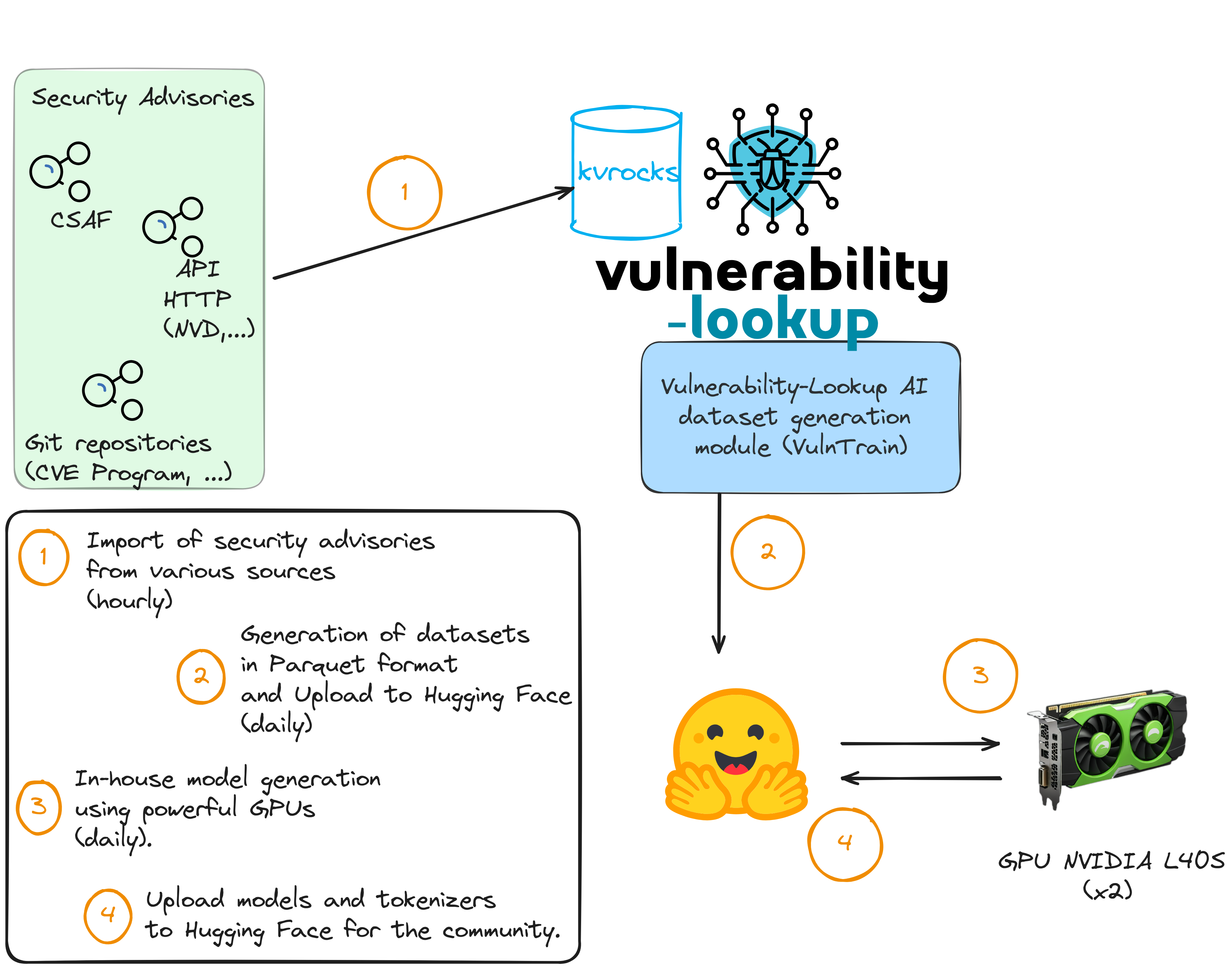
With the various vulnerability feeders of Vulnerability-Lookup (for the CVE Program, NVD, Fraunhofer FKIE, GHSA, PySec, CSAF sources, Japan Vulnerability Database, etc.)
we’ve collected over a million JSON records. This allow us to generate datasets for training and building models.
During our explorations, we realized that we can automatically update a BERT-based text classification model daily using a dataset of approximately 600k rows from Vulnerability-Lookup.
With powerful GPUs, it’s a matter of hours.
Models are generated on our own GPUs and with our various open source trainers.
Similar to the datasets, model updates are performed on a regular basis.
Text classification
vulnerability-severity-classification-roberta-base
This model is a fine-tuned version of RoBERTa base on the dataset
CIRCL/vulnerability-scores.
The time of generation with two GPUs NVIDIA L40S is approximately 6 hours.
Try it with Python:
>>> from transformers import AutoModelForSequenceClassification, AutoTokenizer
... import torch
...
... labels = ["low", "medium", "high", "critical"]
...
... model_name = "CIRCL/vulnerability-severity-classification-roberta-base"
... tokenizer = AutoTokenizer.from_pretrained(model_name)
... model = AutoModelForSequenceClassification.from_pretrained(model_name)
... model.eval()
...
... test_description = "langchain_experimental 0.0.14 allows an attacker to bypass the CVE-2023-36258 fix and execute arbitrary code via the PALChain in the python exec method."
... inputs = tokenizer(test_description, return_tensors="pt", truncation=True, padding=True)
...
... # Run inference
... with torch.no_grad():
... outputs = model(**inputs)
... predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
...
...
... # Print results
... print("Predictions:", predictions)
... predicted_class = torch.argmax(predictions, dim=-1).item()
... print("Predicted severity:", labels[predicted_class])
...
tokenizer_config.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.25k/1.25k [00:00<00:00, 4.51MB/s]
vocab.json: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 798k/798k [00:00<00:00, 2.66MB/s]
merges.txt: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 456k/456k [00:00<00:00, 3.42MB/s]
tokenizer.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3.56M/3.56M [00:00<00:00, 5.92MB/s]
special_tokens_map.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 280/280 [00:00<00:00, 1.14MB/s]
config.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 913/913 [00:00<00:00, 3.40MB/s]
model.safetensors: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 499M/499M [00:44<00:00, 11.2MB/s]
Predictions: tensor([[2.5910e-04, 2.1585e-03, 1.3680e-02, 9.8390e-01]])
Predicted severity: critical
critical has a score of 98%.
Putting Our Models to Work in Vulnerability-Lookup
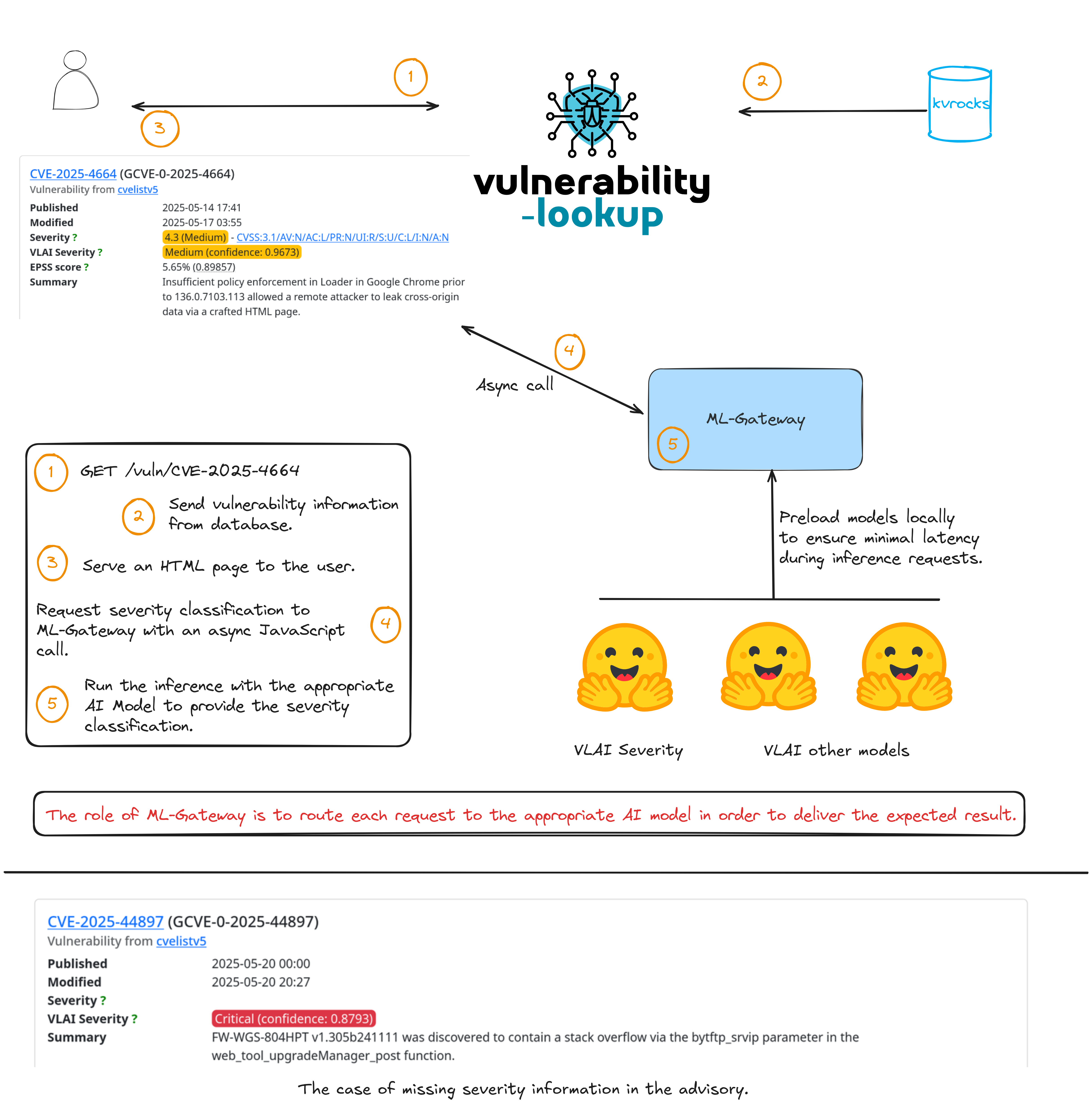
Models are loaded locally in the ML-Gateway to ensure minimal latency. All processing is done locally — no data is sent to Hugging Face servers.
We use the Hugging Face platform to share our datasets and models, as part of our commitment to open collaboration.
ML-Gateway implements a FastAPI-based local server designed to load one or more pre-trained
NLP models during startup and expose them through a clean, RESTful API for inference.
Clients interact with the server via dedicated HTTP endpoints corresponding to each loaded model. Additionally, the server automatically generates
comprehensive OpenAPI documentation that details the available endpoints, their expected input formats, and sample responses—making it easy to explore and integrate the services.
The ultimate goal is to enrich vulnerability data descriptions through the application of a suite of NLP models, providing direct benefits to Vulnerability-Lookup and supporting other related projects.